




Steganography is the study and practice of concealing information within objects in such a way that it deceives the viewer as if there is no information hidden within the object.
I wrote an ariticle about Image Steganography before. Just as the name indicates, image steganography is a way to conceal information in images.
In this article, let's see what unicode steganography is and how to conceal information by this technique.
Zero-width characters
In unicode, there is a type of characters called zero-width space characters. They are valid characters but it rendered with zero width. So even though they exists, people can't see them unless use special tools.
See the image below. How comes the same string ends up with value false?
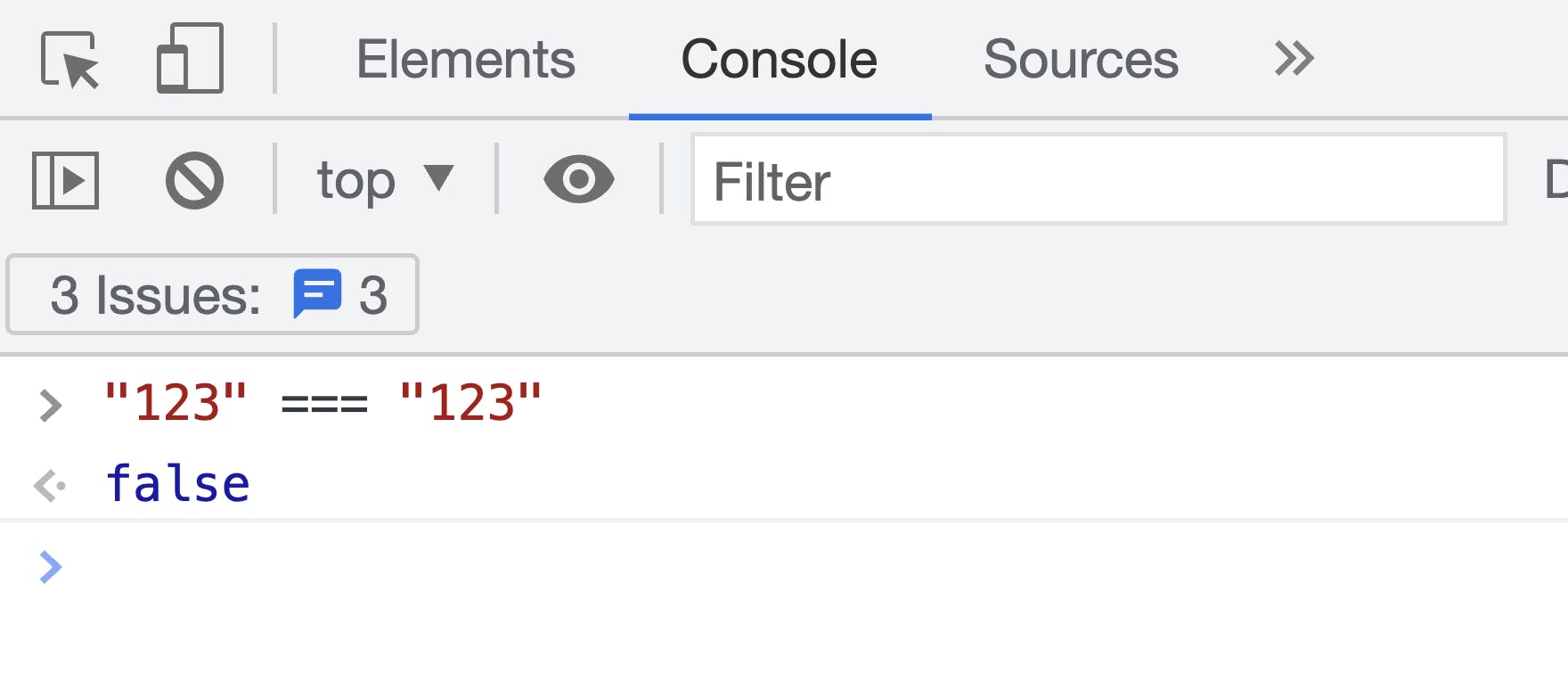
Actually, it just looks like same string, paster this in your browser console to see the result: "123" === "123".
If you paste this in vim, then what you will see is like this.
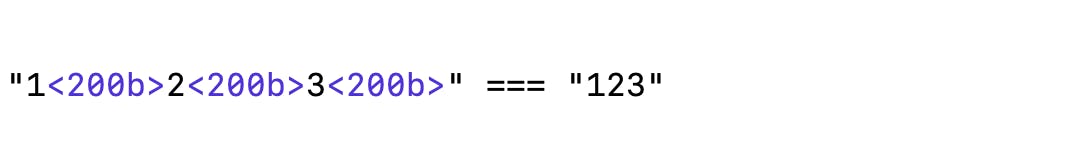
Yes, the left side of is not plain string "123", there are 3 <200b> in the string. This is what we called the zero-width characters. It is hard to type by keyboard. You can use this command copy("\u200B") in chrome console to copy it into clipboard. Or just use the its code point to get the value String.fromCodePoint(8203).
<200b> is not the only zero-width characters. There are other zero-width characters like <200c>, <200d>, etc. These characters have their own purposes, but we can use it for our own purpose.
Unicode Steganography
So we now know there are a few zero-width characters in unicode. Let's see how to use them to hide information.
Once you understand zero-width characters, using to hide information is actually pretty straightforward. There is no formal way to use it, you can design your own way if you want. Now let's see a simple way.
Say we have a normal message, and a secret message. We want to hide secret message into normal message. First, we break secret messages into bytes array. Because each byte can be expressed by 0s and 1s, we can choose one zero-width character to express 0 and another zero-width character to express 1. So we only need to use 2 zero-width characters to express all secret message. And lastly, we insert each bytes(expressed by zero-width characters) into normal message.
With all this in mind, we can implement our own simple unicdoe steganography program.
function encode(message, secret) {
const secretBytes = new TextEncoder().encode(secret);
let secretMessage = [];
const zero = '\u200b';
const one = `\u200c`;
for (const byte of secretBytes) {
// convert each bits into zero-width characters
for (let i = 7; i >= 0; i--) {
if ((byte & (1 << i)) === 0) {
secretMessage.push(zero);
} else {
secretMessage.push(one);
}
}
}
return message + secretMessage.join("");
}
function decode(message) {
const secretBytes = [];
let byte = [];
const zero = '\u200b';
const one = `\u200c`;
for (const char of [...message]) {
if (char === zero) {
byte.push("0");
} else if (char === one) {
byte.push("1");
} else {
continue;
}
if (byte.length >= 8) {
secretBytes.push(parseInt(byte.join(""), 2));
byte = [];
}
}
return new TextDecoder().decode(new Uint8Array(secretBytes));
}
const message = "123456789";
const secret = "Hello, world!";
const encoded = encode(message, secret);
const decoded = decode(encoded);
console.log({ message, secret, encoded, decoded });
Run the program and we can see the result.
{
message: '123456789',
secret: 'Hello, world!',
encoded: '123456789',
decoded: 'Hello, world!'
}