




UTF-8 is an algorithm for encoding character. Before we get to the details of this algorithm, let's first see why we need it.
In computer, all things are bits. Bits can be seen as numbers. So how to express characters with numbers? Answer is using a table to map a number to a character.
The so-called ascii table is a typical one. In ascii, each byte is used to express one character. So in total, ascii can express 256(2^8) number of characters. This is enough for English, but for other language like Japanese, this simple table is definitely not enough.
So to express all the languages in the world, a table called unicode was invented. In unicode, we still use numbers to express characters. In unicode, these numbers are called code point. There are so many characters in the world, so we need big numbers to express them. So instead of 1 byte, in unicode, 4 bytes are used to store one number.
If we use 4 bytes to express all characters, then this is the UTF-32 encoding. This is easy but at the same we may waste a lot of bytes. For example, for small code points, the first 3 bytes may always be 0, only the last byte is used. So to avoid this problem, normally we use UTF-8.
Compared to UTF-32, UTF-8 is a variable length encoding algorithm. Which means for different character, different length of bytes may be used. Compared with fixed length encoding algorithm, variable length encoding algorithm needs to device a mechanism to divide each characters. For example, for UTF-32, we know every 4 bytes stands for a character, so we can just for loop the whole bytes and divide them by 4. But for UTF-8, a character could take 1/2/3/4 bytes. We need to know how to decide which bytes belong to which characters.
With all the above background, let see the details of UTF-8 and see how it solve the above problems.
Take a look at the image blew(taken from wiki).
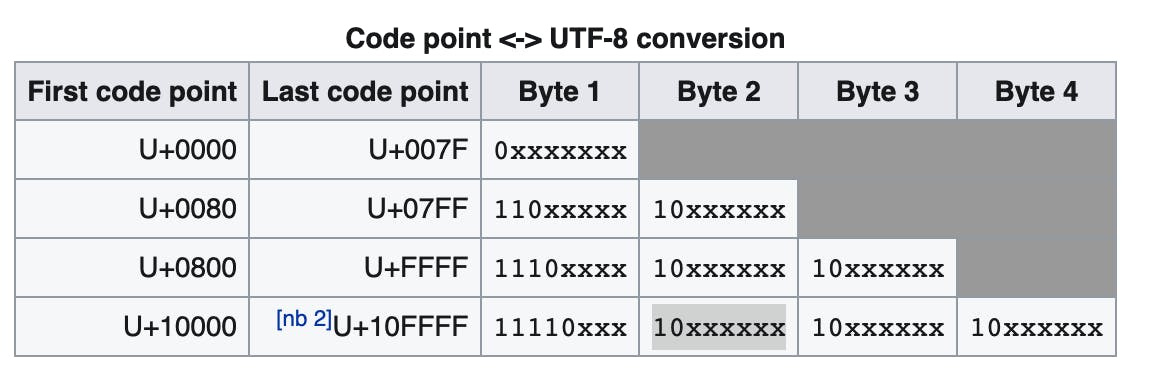
We can see that, in UTF-8, we can check the first several bits to see how many bytes current character takes. For example, if first bit is 11110, then this is the first byte of a 4-byte character. Then bytes start with bits 10 means it is a continue byte, which means that it is not the start byte of a character. Sample code could be like below.
if (byte >> 3 === 0b11110) {
i += 4;
} else if (byte >>> 4 === 0b1110) {
i += 3;
} else if (byte >>> 5 === 0b110) {
i += 2;
} else if (byte >> 7 === 0) {
i += 1;
} else {
throw new Error('invalid byte');
}
With this technique, we can group bytes for the same characters. Next, we need to calculate code point value from bytes. The process is take all other bits, as the all bits of the code point. Set bits from left to right one by one like below.
11110xxx
10xxxxxx
10xxxxxx
10xxxxxx
This process can be achieved by bits operations, like below.
codePoint = ((byte & 0b111) << 18) | (readContinueByte(buf[i + 1]) << 12) | (readContinueByte(buf[i + 2]) << 6) | readContinueByte(buf[i + 3]);
OK, I think that is all we need to know. Let's write a decode function to decode UTF-8 encoded binary values into characters.
function decode(buf: Uint8Array): string {
let i = 0;
let codePoint: number;
let decoded: string[] = [];
function readContinueByte(byte: number): number {
if (byte >> 6 !== 0b10) throw new Error(`invalid byte, expect continue byte: ${byte.toString(2)}`);
return byte & 0b111111;
}
while (i < buf.length) {
const byte = buf[i];
if (byte >> 3 === 0b11110) {
codePoint = ((byte & 0b111) << 18) | (readContinueByte(buf[i + 1]) << 12) | (readContinueByte(buf[i + 2]) << 6) | readContinueByte(buf[i + 3]);
i += 4;
} else if (byte >>> 4 === 0b1110) {
codePoint = ((byte & 0b1111) << 12) | (readContinueByte(buf[i + 1]) << 6) | readContinueByte(buf[i + 2]);
i += 3;
} else if (byte >>> 5 === 0b110) {
codePoint = ((byte & 0b11111) << 6) | readContinueByte(buf[i + 1]);
i += 2;
} else if (byte >> 7 === 0) {
codePoint = byte;
i += 1;
} else {
throw new Error('invalid byte');
}
decoded.push(String.fromCodePoint(codePoint));
}
return decoded.join("");
}
const text = 'Hello, こんにちは、😄';
const buf = new TextEncoder().encode(text);
const decoded = decode(buf);
console.log({text, buf, decoded});
/**
{
text: "Hello, こんにちは、😄",
buf: Uint8Array(29) [
72, 101, 108, 108, 111, 44, 32,
227, 129, 147, 227, 130, 147, 227,
129, 171, 227, 129, 161, 227, 129,
175, 227, 128, 129, 240, 159, 152,
132
],
decoded: "Hello, こんにちは、😄"
}
*/