




Groups
Groups are just sub patterns in regular expressions.
For example, for a normal url match, we will do below.
"http://google.com:443".match("https?://[a-z]+.com")
// ['http://google.com', index: 0, input: 'http://google.com', groups: undefined]
As you can see, the first element in the result array shows the whole matching string. What if we want to get the parts of matching result?
To match the matching parts, we can just make the sub pattern inside ( and ). In this example, let's try to match protocol and host with group.
"http://google.com:443".match("(https?)://([a-z]+.com)")
// ['http://google.com', 'http', 'google.com', index: 0, input: 'http://google.com:443', groups: undefined]
This time, the first element is still the whole match. The second element is the first matching group. The third element is the second matching group.
Nested Groups
Groups can be nested. So we can write groups inside other group. The result of the nested groups follow the the same pattern: from outer pattern to insider pattern, from left pattern to right pattern.
Below example shows the process.
"1289".match(/((1)(2))((8)(9))/)
// ['1289', '12', '1', '2', '89', '8', '9', index: 0, input: '1289', groups: undefined]
Optional Groups
With groups, we can get the sub matching string, but we can also apply other rules for the group level.
For example, in /([a-z]\d)+/, the + character has effect on the group before it.
So, what if we have an optional character after the group like this ()?? Because the group is optional, so it ok to not match. What should be the result?
Well, the answer is simple, we still have the result place ready. If there is no matching, then value is just undefined.
'a'.match(/a(z)?(c)?/);
// ['a', undefined, undefined, index: 0, input: 'a', groups: undefined]
All Groups Matches
If we use global RegExp in the match api, we can't get the results for groups.
'aazazc'.match(/a(z)?(c)?/g)
// ['a', 'az', 'azc']
So to get all matches and all the groups information, we need to use matchAll api. The return value is RegExpStringIterator.

Named Goups
Get groups values from its position is pretty hard and error-prone. We can give each group a name, and later we can get corresponding values from its names.
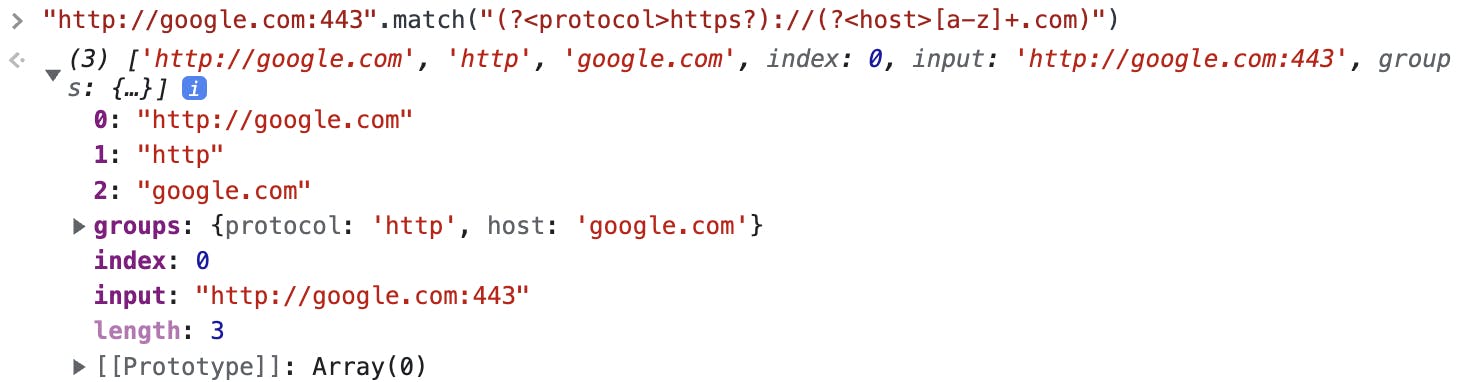
As you can see, all the result is in the groups object.
Non-capturing Groups
All the groups we have seen before is also called capturing group. The meaning is that not only we want to use the group, but also want to get the group's matching result. So if we just use the group for matching code, but we don't want its matching result, then we can use non-capturing groups.
"1212abc".match(/(?:12)+([a-z]+)/)
// ['1212abc', 'abc', index: 0, input: '1212abc', groups: undefined]
In above example, the group (?:12) is just used to match with the + character, so there is no matching value in the result array.
Backreferences
We can use the contents of groups not only in the result, but also in the pattern itself.
Consider a case, we want to match a list of element, it can be as below formats:
1,2,3
1-2-3
1/2/3
What should the RegExp looks like? We may come up with something like this.
"1,2,3".match(/\d[,\-/]\d[,\-/]\d/)
Yes, this is ok. But this RegExp also matches below invalid string.
"1/2,3".match(/\d[,\-/]\d[,\-/]\d/)
So what we really want is, the second separator character should be the same as the first separator. We can use back reference to achieve this.
A group can be referenced in the pattern using \N, where N is the group number. So we will try to match the first separator and then back reference it when trying to match the second separator.
"1/2/3".match(/\d([,\-/])\d\1\d/)
Note here, \1 is used to refer to the first group.
We can also use \k<name> to refer to named groups.
"1/2/3".match(/\d(?<sep>[,\-/])\d\k<sep>\d/)
In this way, we can avoid previous false match.
"1/2,3".match(/\d(?<sep>[,\-/])\d\k<sep>\d/)
// null